Introduction
In the previous lessons, we have covered what the filesystem is, how it's structured, and various concepts involved, such as symbolic links. Soon, it'll be time to get onto the concrete stuff - mounting volumes.
First, however, it's time to get acquainted with yet another of the big principles of the filesystem:
Everything's a file!
One of the brilliant design moves of the UNIX operating system is that everything that can be represented as a file, is represented as a file. A hard disk is a file, a terminal is a file, your webcam is a file - everything.
"What, everything?" I hear you cry. Well, in fact, I don't, because the usual response to this revelation is blank incomprehension. So let's try another route. Try this:
cat /proc/cpuinfo(Linux systems only)
You will see a load of information about the processor(s) on your computer. Bu-bu-but...it's just a file, isn't it? Obviously, there is no such file on your computer's hard disk. Through a trick I will explain later on, the system creates a "virtual" file, and gives as its contents that bunch of CPU info.
ls /dev/
You will see a list of files (coloured yellow if you use the normal set oflscolours). These are special files, also known as device files - these represent devices on your computer.
WARNING!
We are now entering the area where it is possible to damage your system. Reading from or writing to one of these files sends or retrieves data from a device on your system, and can overwrite data or, in extreme cases, damage hardware. The great are not exempt from this - Linus Torvalds once famously lost a lot of data by specifying the wrong device file, and sending commands intended for his modem to his hard drive.
None of the devices we'll be playing with right now can do anything that drastic, and I'll warn you when we get to that point, but do avoid playing with files you don't understand yet, especially those in /dev/.
Find an audio file ending in
.au- Sun' mu-law audio format (There's a famous one somewhere on kernel.org if you can't find one). Now try this:cat somefile.au > /dev/audio
Listen to your speakers as you execute that command - you'll hear that audio file. And yes, it is doing exactly what you think it is. You write the waveform data to a special file, and it comes out of the speakers. Try it the other way round:
cat /dev/audio > my_first_recording.au
Gabble into your microphone a bit, then press
Ctrl+C. Congratulations, you've just made your first recording. Play it back if you like.Now, I don't know about you, but at this point in my exploration of device files, I let out an almighty W00T!, abandoned said exploration, and promptly ran off to do some funky stuff with my sound card that you simply cannot do under other operating systems without learning some very complicated APIs. If you are of a programming turn of mind, and wish to follow in my footsteps at this point (if you're short of a project, here's a hint: simple audio broadcasting is both very fun and relatively easy), look out for
/dev/dsp- it stands for digital signal processor, and is basically a direct interface to the digital-to-analogue convertor on your sound card, as opposed to /dev/audio, which uses slightly weird encoding. Have fun!
-
One more demonstration: Now, this one depends on where you're working - exact names will vary. Whatever the exact filename is, what we're trying to find here is the file which represents the terminal you're working on. If you're working on the console in Linux, then your terminal is probablyWhat's a tty?
You'll hear me using the words "terminal" and "tty" interchangeably. "tty" actually stands for TeleType - the first type of device capable of acting as a terminal for a UNIX system. The name stuck, applying itself to the next step (dumb terminals - a keyboard and a text-only screen, connected to a remote system), right the way up to the present day. In fact, the fancy graphical programs you use to talk to a shell prompt (xterm,konsole, PuTTY et al.) are called terminal emulators, because they copy ("emulate") a dumb terminal./dev/ttyN, whereNis somewhere between1and8. If you're working in X (from xterm, aterm, gnome terminal, konsole, etc), your terminal will probably be/dev/pts/N. On some but not all systems, the commandfingerwill tell you which tty you, and other users currently logged in, are using.To test a tty, write some text to it - the easiest way is
echo Hello > /dev/ttyXYZ(run "echo Hello", which printsHello, and direct its output to whichever tty). You should see "Hello" printed on one of your terminals. Neat, huh? Just try this a couple of times with any likely-looking terminals, and sooner or later you'll find the one you're looking for.
Well, I hope I now have you at least partially convinced of the power that comes from treating everything as a file. Now to actually make use of it.
Commonly used devices
The devices we will use most to start with are the hard drives and floppy
drive. On a PC, /dev/hda is the primary master IDE disk. If you
don't know what that means, and just bought a computer you've never opened and
poked inside, then it's a safe bet that /dev/hda represents your
one and only hard disk. Your second IDE disk (primary slave) is
/dev/hdb. Your third IDE disk (secondary master) is
/dev/hdc - on the vast majority of systems, this is not a hard
disk but a CD-ROM drive. To make things easier, many systems have a symbolic
link at /dev/cdrom, pointing to the actual device (almost always
/dev/hdc). Secondary slave is /dev/hdd, and so on.
Personally, I administer a system which keeps on until /dev/hdg,
and we're thinking about adding more.
Your first floppy drive will be /dev/fd0, your second
/dev/fd1, and so on.
Any of these devices may be present or absent - the fact that there is a file
in /dev/ for it doesn't mean anything!
All of these devices, and in fact most disk devices, are block devices. This means that they can only be written to, read from, and skipped around in multiples of the block size - usually 512 bytes. By contrast, devices such as terminals, serial ports and sound cards are character devices, which can be read from and written to like ordinary files, byte by byte. This becomes important later, when using loopback-mounted filesystems.
Anatomy of a filesystem
Now, back to the UNIX filesystem. Each volume is represented by a block device. As far as the filesystem is concerned, each block device is a one-dimensional array - just a long string of blocks, one after another. Device drivers in the operating system take care of the fact that most data is in fact stored in spirals on spinning disks of various kinds. This is our first layer of abstraction - everything reading or writing data to any device doesn't need to bother about how it's stored, it can just talk to things in exactly the same way. This is good - it means that the driver to handle DOS-formatted floppy disks does not need to be rewritten to handle DOS-formatted hard drives - the layout of the data on the disk is the same, and the hardware drivers take care of the differences for us.
A block device isn't much use to us as-is - we need to be able to store files on it. So, we need some coherent system for storing arbitrary-length streams of data (files), in an organised heirarchy (directories), in a fixed-length stream of data with a fixed block size and no organisation (a storage device). Square peg, round hole.
This is, as you may have guessed, a difficult problem, and as is the way with
such things, it has spawned a legion of solutions, each competing on its various
merits (speed, efficiency, reliability, and so on). If I mention a few examples,
some of them may well sound familiar: FAT16, FAT32,
ext2, ext3, reiserfs, UFS,
HFS, NTFS...and that's only the ones I see on a
regular basis. These I will call filesystem implementations, to
distinguish them from "the filesystem" as an entity, but their normal name is
"filesystems" ("Which filesystem does Solaris usually use?"). A volume
formatted with one of these filesystem implementations is also called a
"filesystem" ("Is there a filesystem on that disk already, or should I format it
myself?"), but I will call them "formatted volumes" to avoid confusing everyone,
myself included.
We don't need to go into specifics of how a filesystem implementation works - entire books have been written about it, and we're still innovating. However, it is good to know how the general system is organised.
The important thing to realise is that this is all about layers of abstraction. The operating system kernel itself is one gigantic abstraction, providing a uniform interface to programs (called system calls), allowing them to use completely artifical constructs such as files and directories, text input and output and network interfaces, rather than forcing them to fiddle with blocks on hard disks, flip bits on a video card, or catch interrupts from an ethernet adaptor, just to do the simplest tasks. This layer of abstraction also allows it to control access to these resources.
Anyway, back to the subject. Let's see how one filesystem transaction happens:
- System call
A program (my text editor) wants to open the file/home/meredydd/Lesson3.html. It asks the kernel to open that file, using theopen()system call (with which some of you will be very familiar). - VFS
Control is now passed to a section of the kernel called the VFS (Virtual Filesystem), whose job it is to figure out what to do with this request. It consults the mount table - a table within the kernel that stores which bits of the filesystem are stored on which devices, using which filesystem implementation. You can view the mount table with themountcommand: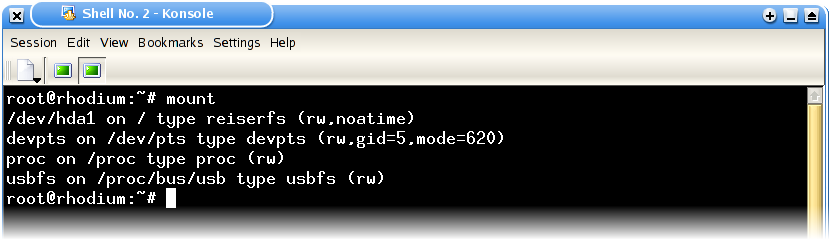
As you can see, my mount table tells me that my root volume (mounted under
/) is/dev/hda1, and that it is using thereiserfsfilesystem implementation. There are also a few other filesystems mounted, all of them irrelevant to this example. The VFS sorts through this table, and figures out which volume is responsible for the directory/home/meredydd- in this case/dev/hda1. - Filesystem driver
The VFS then calls up the driver for the filesystem implementation in use by that volume (in this example,reiserfs), and asks it for information about the file in question. The filesystem driver then reads the appropriate blocks from the device in question (/dev/hda1here), interprets them however it should, and returns the information to the VFS, which then makes vital decisions such as whether the file exists, whether this user has permission to open the file, and so on. - Hardware
As I have said before, the filesystem driver does not actually need to know anything about the hardware on which this data is being stored. The appropriate driver (in this case, the driver for my IDE controller) handles reading and writing the actual blocks on the disk, freeing the filesystem driver from the need to handle the physical stuff.In fact, the system is a bit more complicated - just above the hardware driver is a complicated system of buffers and caches, to ensure that a minimum of time is wasted on hardware reading and writing (which is slow), and frequently-used blocks are instead held in memory (which is a lot faster). Caching also helps to speed up write operations - modified blocks are held in memory until they can be written to the device all at once, which is much more efficient. Unfortunately, this means that if the power is unexpectedly removed, this data never actually gets written to disk, which is why turning off your computer without properly shutting down is a Bad Thing, and can lose data. Filesystems have evolved mechanisms for minimising the damage caused by this and other nasty events - a topic which I will handle in later lessons.